
Using directed rounding in Octave/Matlab#
Created: 2021-12-23
Updated: 2026-05-20
The current IEEE Standard for Floating-Point Arithmetic specifies several rounding modes, which have become accessible to the C/C++ programming languages as part of the C99, C++11, and following standards. GNU Octave and Matlab use in general multi-threaded BLAS/ LAPACK library functions for fast matrix-vector-computations. Depending on the used library, improper thread synchronization might lead to unreliable results when switching the rounding mode using C/C++ functions. This article investigates how to reliably switch the rounding mode in GNU Octave using the performant OpenBLAS library and last resort problem mitigations for Matlab.
Rounding modes: standards and implementations#
Switching the rounding mode is an important tool used by many verification methods based on floating-point arithmetic. The latter being only of finite precision, input data or results of numerical computations with “too long” fractional part have to be rounded to a floating-point number, i.e. a number that fits “nicely” into the computers memory.
The rules for rounding are defined by the IEEE Standard for Floating-Point Arithmetic (IEEE-754 2019, doi: 10.1109/IEEESTD.2019.8766229), which the C99, C++11, and later C/C++ standards refer to in an older version. Those rounding modes with respective C/C++ macros are:
Roundings to nearest
FE_TONEAREST(“ties to even”)(“ties away from zero” is not available in C/C++)
Directed roundings
FE_TOWARDZERO= towards zeroFE_UPWARD= towards +infinityFE_DOWNWARD= towards -infinity
C/C++ functions using the macros above are:
since C99
fesetroundandfegetroundsince C++11
std::fesetroundandstd::fegetround.
Under the hood, for example in the GNU C library (glibc 2.34) the functions fesetround.c and fegetround.c modify or read the active rounding mode from the global x87 FPU Control Status Register and SSE Control Status Register (MXCSR). The state of those registers is part of a running process. During a process context switch the register state (and thus the active rounding mode) is usually saved and restored properly.
With gaining popularity of multi-core processors, using light-weight threads has become more popular in software design. Context switches for threads are designed to be fast. For the sake of performance and depending on the implementation, some register states are not properly synchronized or at worst (partially) reset or cleared.
To overcome implementation-dependency, software libraries like BLAS/LAPACK have to manually take care of synchronizing those register states when starting a new thread. The situation for OpenBLAS is described below.
Further details about the specification and implementation of floating-point arithmetic can be found in many excellent articles and books. To name an exceptional all-encompassing source of information, see section 2.2, sub-section 3.4.4, chapter 6, and sub-section 6.1.3 in Muller et al. “Handbook of Floating-Point Arithmetic” (2018, doi: 10.1007/978-3-319-76526-6) or the respective Wikipedia article.
Changing the rounding mode from Octave/Matlab#
Finally,
the C function fesetround can be called from Octave/Matlab through the
mex-file interface
using the following code setround.c:
#include <mex.h>
#include <fenv.h>
#include <float.h>
#pragma STDC FENV_ACCESS ON
void mexFunction ( int nlhs, mxArray *plhs[],
int nrhs, const mxArray *prhs[] ) {
int rnd = (int) mxGetScalar (prhs[0]);
int mode = FE_TONEAREST;
switch (rnd)
{
case -1:
mode = FE_DOWNWARD;
break;
case 0:
mode = FE_TONEAREST;
break;
case 1:
mode = FE_UPWARD;
break;
case 2:
mode = FE_TOWARDZERO;
break;
default:
mode = FE_TONEAREST;
break;
}
fesetround (mode);
}
which can be compiled with:
mex --std=c11 setround.c % Octave
mex ('CFLAGS="$CFLAGS --std=c11"', 'setround.c') % Matlab
Switching the rounding mode to +infinity would be done with the call:
setround (+1);
See setround.c for analogous calls for other rounding modes.
This approach of switching the rounding mode is most notably used by INTLAB or the Interval package.
The issue: parallel matrix computation#
For “small” (single-threaded) computations (thus mostly scalars)
the function setround works fine.
e = eps () * eps (); % smaller than machine precision
setround (+1); % round to +inf
num2hex (1 + e)
ans = 3ff0000000000001
setround (-1); % round to -inf
num2hex (1 + e)
ans = 3ff0000000000000
However, the strength of Octave and Matlab is the ease and speed of matrix and vector computations. Therefore, it is desirable to perform those calculations using directed rounding modes as well.
e = eps () * eps (); % smaller than machine precision
setround (+1); % round to +inf
a = ones(100) + e;
a_sup = a * a; % use BLAS (multi-threaded)
setround (-1); % round to -inf
a_inf = a * a; % use BLAS (multi-threaded)
% The following value must be "0" (all values differ),
% if rounding mode switching works correctly.
sum (a_inf(:) == a_sup(:))
As outlined above,
Octave and Matlab use in general multi-threaded BLAS/LAPACK implementations
for matrix and vector computations.
The thread synchronization of the rounding mode
(in the global register state)
is often neglected by those BLAS/LAPACK implementations
for the sake of performance
and the code listing above returns a value larger than 0
(which means computing with setround (+1) or setround (-1)
makes no difference at all).
For example OpenBLAS offers an optional compile flag
CONSISTENT_FPCSR = 1
for manual rounding mode synchronization.
See
driver/others/blas_server_omp.c:
static void exec_threads(blas_queue_t *queue, int buf_index){
// ...
#ifdef CONSISTENT_FPCSR
__asm__ __volatile__ ("ldmxcsr %0" : : "m" (queue -> sse_mode));
__asm__ __volatile__ ("fldcw %0" : : "m" (queue -> x87_mode));
#endif
Using this compile flag has already been suggested by Masahide Kashiwagi (and information on Apple M1 chips) and by INTLAB.
However, most Linux distributions provide OpenBLAS libraries without this compile flag set. And the situation seems similar for other BLAS/LAPACK implementations like the Intel MKL.
Therefore the remainder of this article deals with
how to replace the default OpenBLAS version with a custom one
compiled with the CONSISTENT_FPCSR=1 flag set and,
alternatively,
how to ensure that only a single computation thread is used
in Octave and Matlab,
a slow and impractical last resort solution.
Octave on Microsoft Windows#
It is assumed, that octave-6.4.0-w64-installer.exe from https://www.octave.org/download has been successfully installed.
Option 1 - Single computation thread (slow)#
Go in the Windows Explorer to the GNU Octave installation folder, for example:
C:\Octave\Octave-6.4.0\
and right-click on the octave.vbs (“edit”):
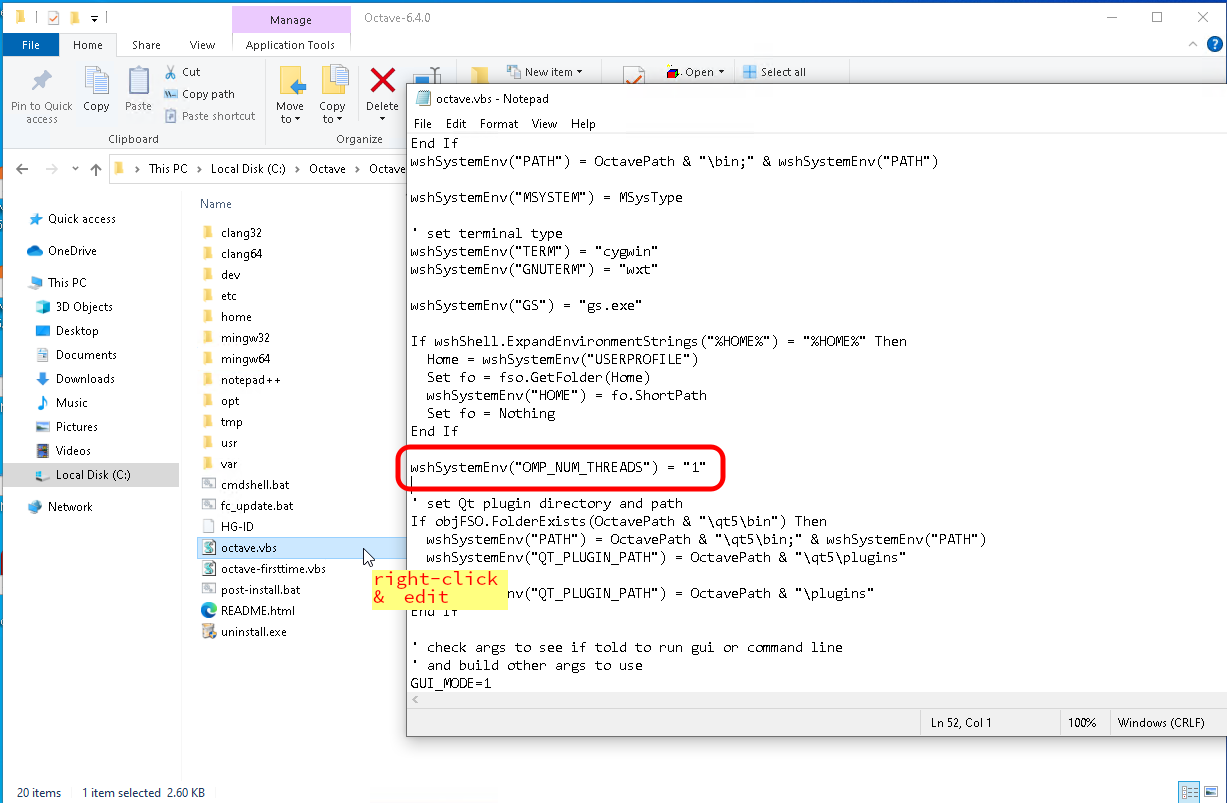
and add in the text editor the line:
wshSystemEnv("OMP_NUM_THREADS") = "1"
as shown in the screenshot above and start Octave as usual.
Option 2 - Replace libblas.dll#
Download the file compiled dynamic-link library (DLL) for OpenBLAS:
libopenblasFPCSR-0.3.18.dll Below the DLL-file creation is described.
For the next steps administrator privileges might be required. Click yes of you are prompted for confirmation.
Put the DLL-file in the directory
C:\Octave\Octave-6.4.0\mingw64\bin
like in the screenshot below:
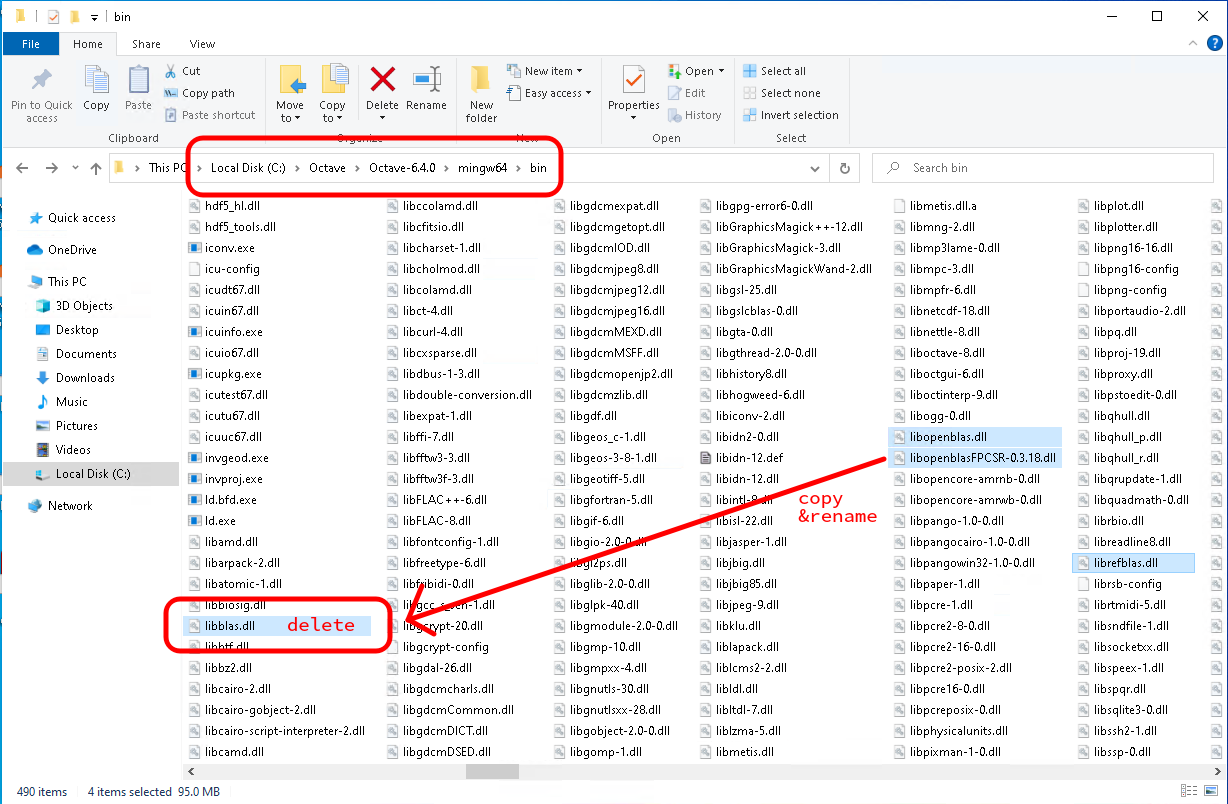
Delete the file libblas.dll.
Copy libopenblasFPCSR-0.3.18.dll and rename the copy to libblas.dll.
If you want to undo this change: Delete the file
libblas.dllagain.Copy
libopenblas.dlland rename the copy tolibblas.dll.
How to create
libopenblasFPCSR-0.3.18.dllOne can make use of the MXE Octave project to cross-compile Octave for MS Windows on Linux.
hg clone https://hg.octave.org/mxe-octave cd mxe-octave ./bootstrap ./configure \ --enable-devel-tools \ --enable-binary-packages \ --with-ccache \ --enable-octave=releaseEdit the file
mxe-octave/src/openblas.mkand add about line 28 to$(PKG)_MAKE_OPTSthe compile flagCONSISTENT_FPCSR=1.Then compile the project (this might take a few hours):
make JOBS=8 all openblasFinally find the OpenBLAS DLL in:
mxe-octave//usr/x86_64-w64-mingw32/bin/libopenblas.dllRename and use it as described above.
Octave on macOS#
It is assumed, that GNU Octave is installed via Homebrew https://brew.sh/:
brew install octave
Option 1 - Single computation thread (slow)#
Start Octave from the Terminal with this command:
OMP_NUM_THREADS=1 octave --gui
Option 2 - Rebuild OpenBLAS#
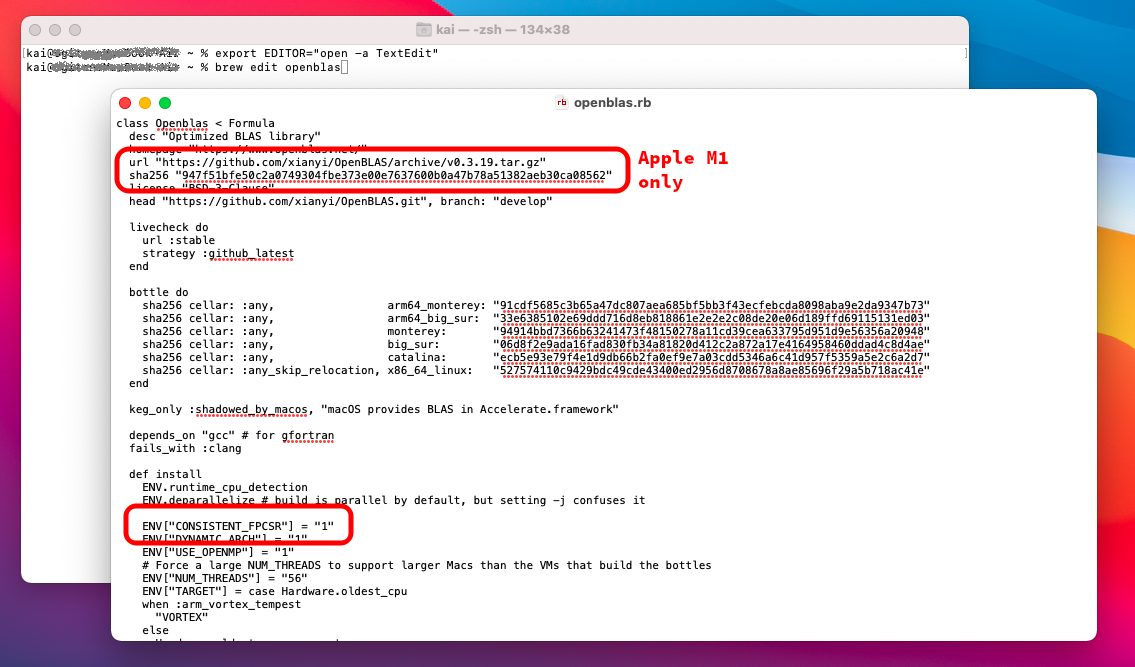
Edit the Homebrew Formula for OpenBLAS:
export EDITOR="open -a TextEdit" # optional
brew edit openblas
and add the line in the “def install” section
ENV["CONSISTENT_FPCSR"] = "1"
like in the screenshot below:
EDIT: 20206-05-20
As part of this project, on 2022-09-22 the OpenBLAS project accepted a patch for Apple M1+ (aarch64 architecture) with the OpenBLAS release v0.3.22: 84453b9.
Full credit for the idea of this patch is to Masahide Kashiwagi in the previously mentioned blog post on Apple M1 chips.
A previously here described OpenBLAS source code patching is no longer required.
Finally run from the Terminal:
export HOMEBREW_NO_INSTALL_FROM_API=1 # Ensure to use local changes
brew uninstall --ignore-dependencies openblas
brew reinstall --build-from-source openblas
The compilation and installation might take about 15-20 minutes.
If you want to undo this change:
cd /usr/local/Homebrew/Library/Taps/homebrew/homebrew-core git restore Formula/openblas.rb brew uninstall --ignore-dependencies openblas brew install openblas
Octave on Linux#
Option 1 - Single computation thread (slow)#
Start Octave from the Terminal with this command:
OMP_NUM_THREADS=1 octave --gui
Option 2 - Rebuild OpenBLAS#
Note: This approach does not work with Snap, Flatpak, or Docker installations of GNU Octave.
Download and extract the OpenBLAS source code:
cd /tmp
wget https://github.com/xianyi/OpenBLAS/archive/refs/tags/v0.3.19.tar.gz
tar -xf v0.3.19.tar.gz
cd OpenBLAS-0.3.19
Build OpenBLAS (note: if you compiled Octave with
ilp64
add the flags BINARY=64 INTERFACE64=1 to the make command)
this should take about 5-10 minutes:
make -j8 \
CONSISTENT_FPCSR=1 \
USE_THREAD=1 \
USE_OPENMP=1 \
NUM_THREADS=256
Then locally install the library:
make install PREFIX=$HOME
Finally start Octave with this command
(the part _haswell might differ depending on the used CPU):
LD_PRELOAD=$HOME/lib/libopenblas_haswellp-r0.3.19.so octave --gui
>> version -blas
ans = OpenBLAS (config: OpenBLAS 0.3.19 NO_AFFINITY USE_OPENMP HASWELL MAX_THREADS=256)
Matlab#
In an
undocumented feature-function
Matlab offers an implementation,
similar to setround above:
feature ('setround', mode); % mode = 0, 0.5, +Inf, or -Inf
However,
this function has the same limitations as setround
and as it is no official function,
it is not expected to work reliably.
With every new Matlab release the thread synchronization
of the underlying
Intel MKL
works more of less reliable.
At the time of writing,
Matlab R2020b is known to work,
while Matlab R2021a is not.
A known reliable workaround is to force Matlab to only use a single
computations thread with the startup option -singleCompThread.
This works on
MS Windows,
macOS, and
Linux.
Summary#
In this blog post the issue of reliably changing the rounding mode for basic linear algebra operations within multi-threaded BLAS/LAPACK libraries using C/C++ instructions from Octave and Matlab was investigated.
While Octave can address this problem by using a customized OpenBLAS or slower reference BLAS/LAPACK implementation, each Matlab release must be evaluated for limitations of the underlying Intel MKL. A solution of last resort for both Octave and Matlab is enforcing a single computation thread, sacrificing all benefits of having multiple CPU cores available.
The proposed solutions do not apply for graphics processing units (GPUs), and associated numerical libraries, as the architecture and command set differs significantly from the CPU.